AC297R - Google
- Overview
- Motivation
- Datasets
- Literature Review
- Application: GTSRB
- Adversarial Training with Data Augmentation
- Conclusion
Overview
In partnership with Google Brain this project explores the field of adversarial examples, inputs designed to trick neural networks, with the goal of making them more accessible to learn about. Starting with motivation, we explain what adversarial examples are and why they are important. From there we review the datasets we use and the literature of adversarial examples. Finally, we share results we have from testing some experimental adversarial defense methods.
Motivation
As Machine Learning is becoming more ubiquitous, understanding how neural networks are learning is becoming increasingly important. Our project explores the field of adversarial examples, which challenges the common belief that neural networks are learning patterns in the data.
What is an Adversarial Example?
Adversarial examples are inputs that have been crafted specifically to trick a neural network, while still being easily discernible to humans. An example of an adversarial example in the context of image classification can be seen below:
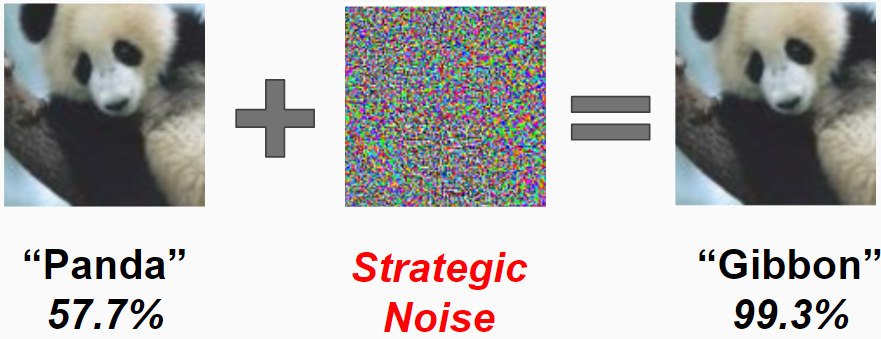 While both the left and right images look like a panda, the right image is improperly classified as a gibbon. This misclassifciation is caused by the addition of strategic noise. The existence of such examples calls into question how and what neural networks of learning.
While both the left and right images look like a panda, the right image is improperly classified as a gibbon. This misclassifciation is caused by the addition of strategic noise. The existence of such examples calls into question how and what neural networks of learning.
Datasets
For this project we worked on the MNIST, CIFAR-10, and GTSRB datasets. We decided to use MNIST and CIFAR-10 because our project was heavily research focused, and most of the literature worked on image classification on these two classic datasets. This decision made it easy for us to compare model performance to the literature and iterate quickly on experimental model setups. We used the GTSRB dataset as a starting point for an application to driverless cars because the dataset is images of traffic signs.
The MNIST dataset is a classic image classification dataset that features 28x28 greyscale images of handwritten digits. There are 10 classes (digits from 0-9), and the dataset contains 60,000 training examples and 10,000 test examples. Below are some images from the MNIST dataset:

CIFAR-10 is another image classification dataset that contains 32x32 color images of 10 classes. Classes consist of various objects and animals such as airplanes, deer, and trucks. There are 60,000 training example sand 10,000 test examples. Below are some images from the CIFAR-10 dataset:

The GTSRB (The German Traffic Sign Recognition Benchmark) dataset consists of images ranging in size from 15x15 to 250x250 of German traffic signs. There are 43 distinct classes of signs and over 50,000 total images. Below are images from the GTSRB dataset:

Literature Review
Adversarial examples are relatively new to the machine learning community, yet they have already accumulated a rich history in literature.
Research on adversarial examples can be broadly classified into two main avenues. Many of the earliest results focused on attack methods for systematically generating images that fool advanced machine learning models to into misclassifying the input. Recently, there has been much interest in analyzing the other side of the coin - i.e. defense methods for protecting models against adversarial attacks.
In this section, we give a quick overview of the attack and defense literature, placing special emphasis on the results that are most pertinent to our own research project.
Attack: Fast Gradient Sign Method (FGSM)
The concept of an adversarial example was invented by Szegedy et al. in 2013 1 and formalized by Goodfellow et al. in 2014 2. In the same paper, Goodfellow et al. introduced Fast Gradient Sign Method (FGSM), which is a simple and intuitive way to generate adversarial examples.
Let’s say we have an input image that we wish to transform into an adversarial example , where is the space of all possible images. Let the model we wish to attack have pre-trained parameters using some loss function . Then, given a step size parameter , FGSM generates with the following gradient update:
where is the vectorized sign function. The intuition for FGSM comes from the idea that adversaries would want to slightly perturb the original image in the direction of the loss function’s gradient, so that corresponds to a higher loss than . Here we use the sign of the gradient instead of the actual gradient so as to ensure that each pixel of is perturbed by at most — a change that should be unrecognizable to the human eye.
Note that FGSM is an untargeted attack, because the adversary has no control over which specific class the model will classify , since was created with the sole purpose of increasing the loss function as much as possible.
Attack: Jacobian-Based Saliency Map Approach (JSMA)
In 2016, Papernot et al. published an effective adversarial method for targeted attacks called the Jacobian-Based Saliency Map Approach (JSMA)3. Let the original image of pixels be with true class where is the total number of possible classes. Let be a -dimensional one-hot encoding of . In a neural network with parameters , the loss function is commonly defined as the cross-entropy between the data’s distribution and the model’s distribution,
where denotes the dot product and is the -dimensional output of the final layer of the neural network. Note that is also a vector of probabilities in which the th entry denotes the probability that the neural network assigns to class .
JSMA is centered around computing the Jacobian matrix , an -by- matrix where entry is defined as
Intuitively, we can think of as how much we would increase the probability of the neural network classifying the image as class if we were to slightly perturb pixel . Now, suppose an adversary is interested in constructing an adversarial example that the neural network will foolishly classify as some target class . Then, the adversary can simply do the following:
- Compute the Jacobian matrix for the current image .
- Use to identify a couple of pixels that we can perturb to decrease the probability of class and increase the probability of class .
- Make these perturbations to create an adversarial image .
- Update . Repeat steps 1-3 until the network misclassifies as target class .
Note that unlike FGSM, JSMA applies strategic perturbations to specific pixels instead of uniformly changing the entire image. Though this method is quite effective at targeted misclassification, it is computationally expensive because the Jacobian matrix must be recomputed at each iteration of the attack.
Attack: Projected Gradient Descent (PGD)
Projected Gradient Descent (PGD) is an iterative application of FGSM on the loss function . It was created by Madry et al. in 2017 4. Let be the original image with pixels. The parameters of PGD are the maximum distortion parameter , the step size parameter , and the number of iterations . At each iteration of PGD, the attack algorithm will produce a newly perturbed image . The final output will be the created adversarial example .
PGD differs from FGSM in two main ways. First, the authors found that randomly initializing the starting point of the gradient ascent leads to more robust adversarial results. Thus, PGD begins by choosing a starting point uniformly at random from within an -dimensional hypercube centered at with side length . Second, PGD performs not one, but steps of the basic FGSM algorithm with step size . At any given point, we may need to clip the perturbations to ensure that the cumulative distortion from the original example does not exceed for all pixels. The full PGD algorithm is given below.
- Let where .
- For each iteration
- Do an FGSM step and compute .
- For each pixel
- If , then clip the cumulative perturbation by setting .
- If , then clip the cumulative perturbation by setting .
- Return adversarial example .
The intuitive advantage of PGD over FGSM is that the former takes small steps to iteratively approximate the gradient instead of taking one large step like the latter. Thus, PGD is able to increase the loss function more efficiently.
Attack: Other Methods
Our research focused on the aforementioned attack methods, but there are many more in literature. These include the Iterative Least-Likely Class Method (ILLC), Carlini and Wagner’s Attack (C&W), Zeroth Order Optimization (ZOO), and more. A comprehensive list can be found in Yuan et al.’s 2017 literary review 5.
All of the methods mentioned thus far are known as “white box” attacks, because they require the adversary to have access to the model’s parameters in order to generate adversarial examples. However, in 2016, Papernot et al. introduced a generic strategy for transferring these “white box” methods into “black box” ones in which such parameters are unknown 6. An adversary can use this method as follows,
- Observe input images that are fed into a model and the corresponding classifications that come out.
- Use this set of pairs as the training set for a neural network that will mimic the behavior of the original model (which is treated as a “black box”).
- Generate an adversarial example for the mimicking neural network using an aforementioned “white box” attack.
- Feed the adversarial example to the original model. It should force the original model to misclassify, assuming that the mimicking neural network is accurate in matching the original model’s behavior.
Defense: Adversarial Training
Goodfellow et al. established the first known method of preparing models to defend against adversarial examples in their seminal 2014 paper 2. Adversarial Training is the simple idea of building adversarial examples into the training set. More specifically, during the training procedure of a neural network, let there be an image with true class . The network has parameters and a loss function that we can use to generate an adversarial examples via one of the attack methods introduced earlier. Then, we can add to the original training set and our model will have seen adversarial examples during training, thereby making it more robust to future attacks.
Defense: Other Methods
Adversarial Training has proven to be quite an effective measure for defending against adversarial examples. In fact, it is arguably the only robust defense method that has been invented. Many other proposals, such as Adversarial Detecting, Ensembling Weak Defenses, and Gradient Hiding, have been shown to be easily defeated in practice 5.
Therefore, part of our research project involved investigating new data augmentation methods that could be used in concert with adversarial training to defend against adversarial examples. Specifically, we explore mixup and random erasure as data augmentation techniques.
Adversarial Examples Tutorial
We have created a Jupyter Notebook-based tutorial on how to create and defend against adversarial examples. The tutorial uses the CleverHans Library in concert with Keras to teach attack/defense methods on simple datasets such as MNIST and CIFAR-10. You can access this tutorial here.
Application: GTSRB
We used the GTSRB dataset to simulate how adversarial attacks and defenses would work in the setting of driverless cars. In addition to having the properties mentioned in the above section, the GTSRB dataset also has some adversarial literature that we benchmark against. Aung et al demonstrate many of the aforementioned attack and defense methods on GTSRB and experiment with methods for making neural networks more robust 7.
Accuracy vs. Perturbation Trade Off
In the paper by Aung et al, the step parameter, , for FGSM is analyzed to see how it affects accuracy 7. We furthered this analysis by testing if we could use the Gini coefficient to determine an optimal that would significantly reduce the classifier’s accuracy while preserving the original image. We use Gini as a measure of the impurity because higher Gini values indicate a very uncertain classifier and that the image is closer to random noise.
Below are four adversarial examples of the same traffic sign with different parameters:
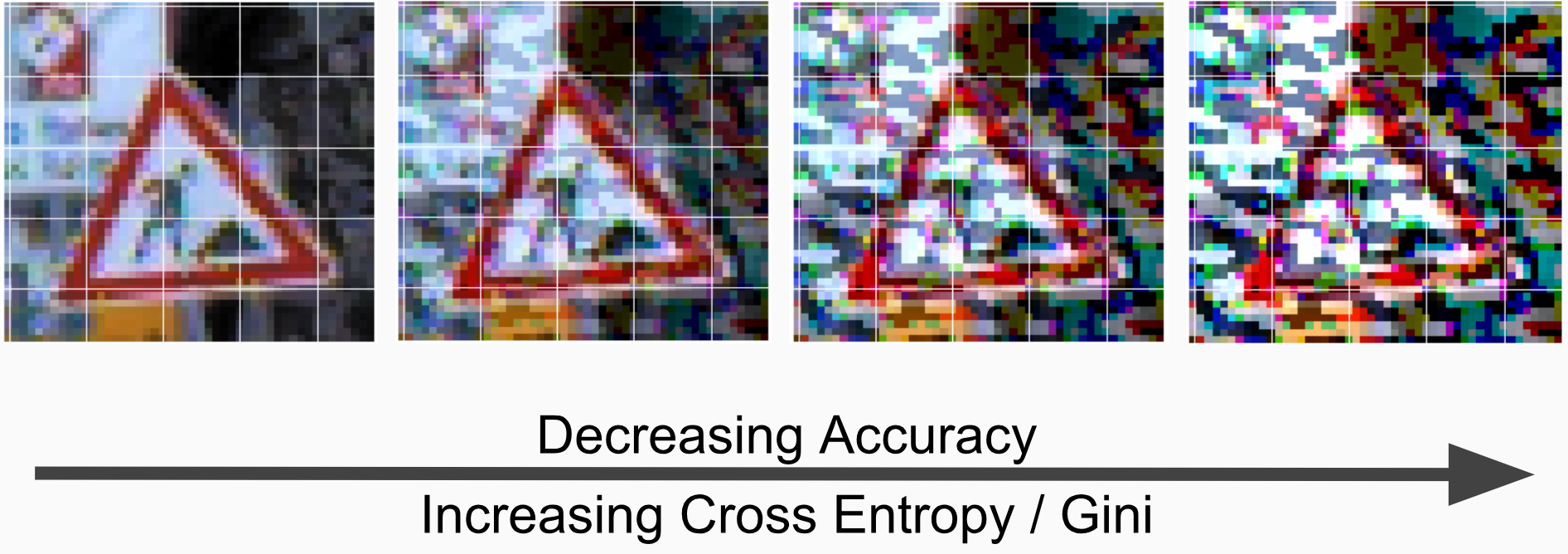
The images on the left side have smaller ’s and resemble the original image quite well. As increases, however, the image becomes more perturbed and eventually more like random noise than an actual sign. To see how affects accuracy and Gini we swept over a range of ’s and found the accuracy and Gini of the test set for each .
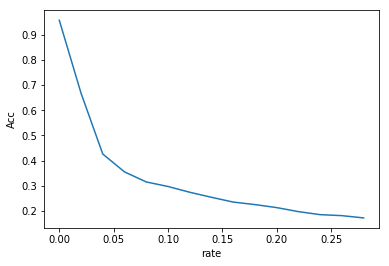
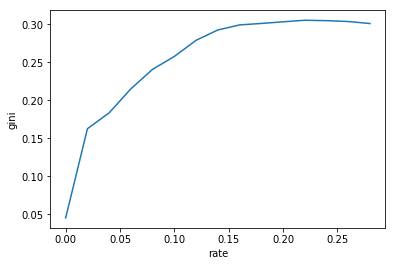
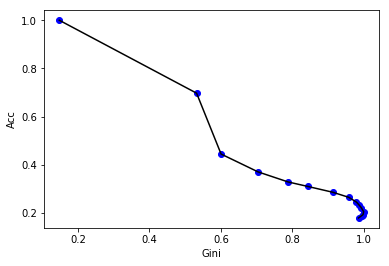
These are plots that show how accuracy and Gini change as increases. As expected a larger reduces accuracy and also increases the Gini coefficient. In order to pick an optimal value we plotted Accuracy vs Gini and tried to use the elbow method to find an epsilon that balanced accuracy and input impurity.
Adversarial Training with Data Augmentation
A major component of this research project involved investigating ways to train models for defense against adversarial examples. Upon consulting with our Google partner, we identified combining adversarial training with data augmentation as a promising research direction. Data augmentation is a process in which we somehow alter the training data before using it to train the model. The specific data augmentation methods that we examined are mixup and random erasure. Work on mixup seems promising, yet we mostly obtained negative results for random erasure.
Mixup
In 2017, mixup was introduced by Zhang et al. as a method to construct virtual training examples by interpolating between two different points in the training set 8. First, choose two images and that belong to two different classes and . Note that and are one hot-encoded. Then, mixup generates a new image with a new class that is defined as follows:
for some value . The original authors chose to draw from a distribution, where is a predetermined hyper-parameter. This new image is a linear interpolation between the two original images and has a corresponding class that is the same linear interpolation between the two original classes. We add this newly constructed pair to our training set.
Here are some examples of mixup on MNIST images.
The intuition behind mixup is that it can help the model “smooth out” decision boundaries between two different classes by letting it train on points between them. If points from class A and class B are well-separated, then the decision boundary assigned by the model could fluctuate between being very close to points in class A and being very close to points in class B. However, with mixup, we can ensure that the decision boundary will be halfway between the class A points and the class B points. Thus, an adversary will be less likely to take advantage of a sharp decision boundary in using gradient ascent-based methods to create adversarial examples. In fact, Zhang et. al present some results showing that training models with mixup can improve robustness to adversarial examples on the ImageNet dataset 8.
Our contribution mainly involved combining mixup with adversarial training.
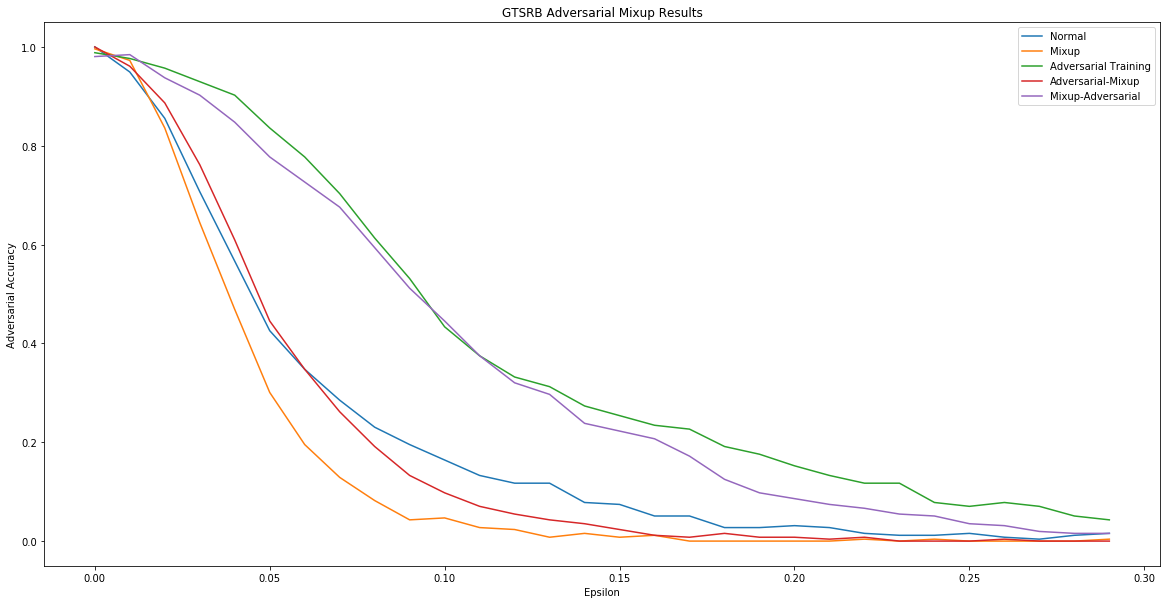
Here are some results from our experiments. We tested how five models that were trained differently (i.e. Normal, Mixup, Adversarial Training, Mixup Adversarial Training, Adversarial Mixup Training) reacted to adversarial attacks on the MNIST dataset. The y-axis denotes “Adversarial Accuracy” (i.e. the accuracy that each model achieved on classifying adversarial examples that were generated using FGSM). It is a function of the x-axis, which varies the FGSM parameter that was used in the attacks.
The different models varied in the ways in which their training sets were preprocessed. The “Normal” model was trained in a standard manner with no adversarial training and no data augmentation. The “Mixup” model was trained using mixup and the “Adversarial Training” model was trained using FGSM-based adversarial training. The “Mixup Adversarial Training” model first mixed up images and then applied adversarial training to these images. The “Adversarial Mixup Training” model did the opposite – first generating adversarial images and then mixing those adversarial images up. All models used the same basic architecture – a simple, feedforward neural network with a couple of hidden layers.
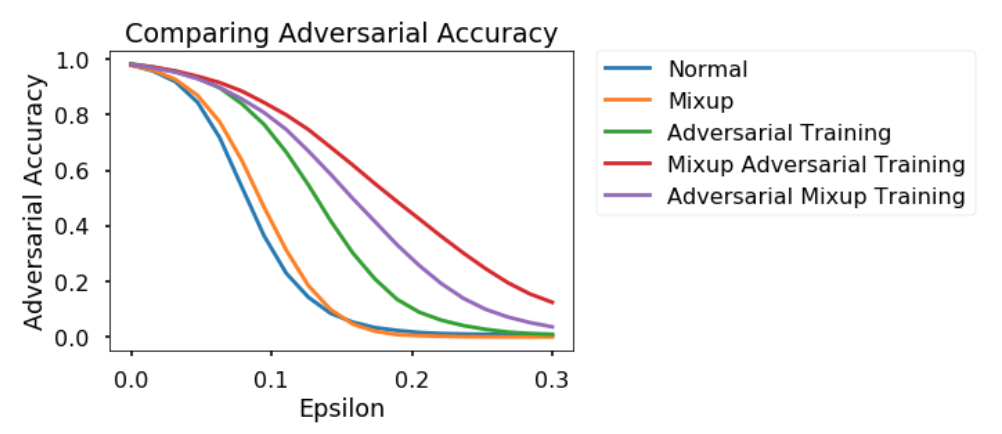
The results show that the “Mixup Adversarial Training” model performed the best in defending against adversarial attacks. Both this model, and the “Adversarial Mixup” model, proved to be more effective for this dataset than either the simple “Adversarial Training” model or the simple “Mixup” model. This suggests that combining adversarial training with mixup may hold some promise in defending neural networks.
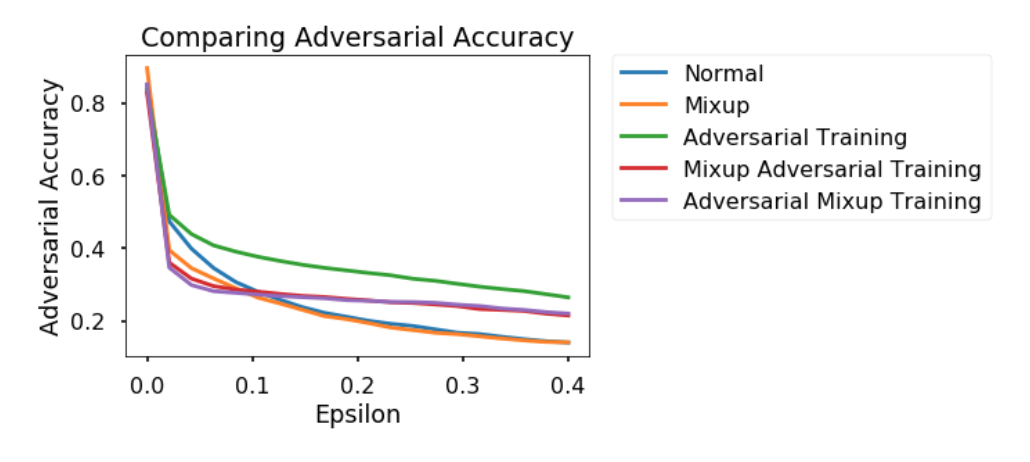
Here is the same experiment done on CIFAR-10. These are the results. They show some positive relationships, but are less supportive of the idea that mixup provides some additional support to adversarial training.
We repeated the same experiment on the GTSRB dataset using PGD instead of FGSM.
Random Erasure
Random erasure is another data augmentation method that was originally designed by Zhong et al. in 2017 as a way to help convolutional neural networks fight overfitting 9. We explore random erasure in concert with adversarial training as an adversarial defense strategy.
The idea behind random erasure very simple: given an image , cut out a randomly chosen rectangular region and replace it with randomly generated pixels to create an augmented image . The class of the augmented image is the same as the class of the original image . The pair is added to our training set.
Here is an example of a CIFAR-10 image with random erasure applied to it.

By blocking out parts of an image, random erasure is designed to prevent models from attending to random patches in the background of an image, thereby helping them “learn” better.
We investigate if random erasure can be used to improve the robustness of models with respect to adversarial examples. We consider the efficacy of random erasure both alone and with adversarial training.
Here are the results using FGSM on a CIFAR-10 dataset.
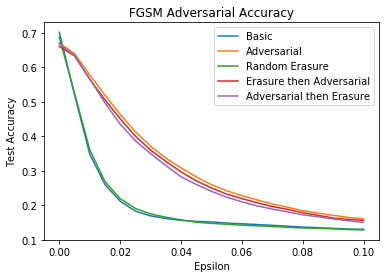
From this graph, we see that random erasure provides no improvement over the basic model and also no additional improvement over a model with adversarial training. Therefore, this method of data augmentation looks less promising than mixup.
Conclusion
In this project, we explored the growing field of adversarial examples, looking at both attack and defense techniques. Adversarial examples are certainly an important aspect of machine learning that must be examined further, as they illustrate how powerful neural networks that are ubiquitous in daily life can be easily fooled. From our defense research, we conclude that mixup shows some promise of being a useful defense tactic, especially when combined with adversarial training. In the future, we would definitely like to explore how other methods can be used to form effective defenses. On the attack side, it would be interesting to look into adversarial examples on discrete input spaces (such as language) and how to construct them when computing the gradient is not possible.
-
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv preprint arXiv:1312.6199, 2013. ↩
-
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014. ↩ ↩2
-
N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The limitations of deep learning in adversarial settings,” in Security and Privacy (EuroS&P), 2016 IEEE European Symposium on. IEEE, 2016, pp. 372–387. ↩
-
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv preprint arXiv:1706.06083, 2017. ↩
-
X. Yuan, P. He, Q. Zhu, R. Bhat, and X. Li, “Adversarial examples: attacks and defenses for deep learning,” arXiv preprint arXiv:1712.07107, 2017. ↩ ↩2
-
N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. Berkay Celik, and A. Swami, “Practical black-box attacks against machine learning,” arXiv preprint arXiv:1602.02697, 2016. ↩
-
A. Aung, Y. Fadila, R. Gondokaryono, and L. Gonzalez “Building Robust Deep Neural Networks for Road Sign Detection,” arXiv preprint arXiv:1712.09327, 2017. ↩ ↩2
-
H. Zhang, M. Cisse, Y. Dauphin, and D. Lopez-Paz, “Mixup: beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017. ↩ ↩2
-
Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” arXiv preprint arXiv:1708.04896, 2017. ↩